
CAT 2026 VARC 40+ Strategy: Why Accuracy Trumps Attempts for Serious Aspirants

Quick Takeaways Before You Begin
What is considered a good CAT 2026 VARC score? A raw score of 38–45 in VARC typically places you at the 85th–95th percentile, depending on the paper's overall difficulty. For top IIMs, a VARC score north of 40 is the threshold most serious aspirants aim for.
Why do many students underperform in VARC despite being good readers? Because VARC is not a reading test. It is a decision-making test. Most underperformers attempt too many questions, fall into inference traps, and misread tone — not because they lack English skills, but because they lack a structured selection and verification discipline.
What is the 80% Confidence Rule? The 80% Confidence Rule is VerbalHub's core VARC framework: attempt a question only when you are at least 80% confident in your answer before committing. If you cannot reach that threshold — through passage understanding, option elimination, or logical reasoning — you skip the question. Strategic skipping is not weakness. At the 90+ percentile level, it is the norm.
The Myth That Is Destroying Your VARC Score
Here is a pattern that plays out in almost every CAT mock: a student reads all four RC passages, attempts 22–24 questions, feels reasonably satisfied — and then gets a VARC score in the low 20s or high teens.
They did not underperform because of poor English. They underperformed because of poor decisions.
The dominant myth in VARC preparation is that more attempts equal a better score. It sounds logical. More shots, more chances, more marks. In most competitive exams, this is broadly true. It is among the costliest errors you can make in CAT VARC.
Here is why. CAT RC options are engineered to be close. Dangerously close. An option that is "mostly right but slightly overstated" sits next to the correct answer. An option that is "true based on real-world knowledge but not supported by the passage" is specifically designed to attract confident, well-read aspirants. An option that "sounds like what the author meant" is not the same as what the author actually said.
The result: smart, well-read students with strong English backgrounds attempt more questions, fall into more inference traps, accumulate more negative marks, and finish with lower percentiles than students who attempted fewer questions but with greater precision.
The biggest VARC mistake is not poor English. It is poor decision-making.
CAT 2026 VARC will reward those who understand this. This article will show you exactly how to build the discipline, the selection logic, and the preparation system to get there.
Why CAT 2026 VARC Demands Precision Above Everything
Close Options, Not Easy Ones
IIM Lucknow, which conducts CAT, has consistently designed RC options that operate at the inference layer. You are rarely asked: "What did the author say?" You are asked: "What did the author imply?" and " Which of these best fits the logic of the author’s argument?"
The difference between correct and incorrect options in many RC questions is not factual — it is a matter of degree. An option might be "supported" vs "strongly supported." An option might be "implied" vs "directly stated." These distinctions require precision reading, not speed reading.
When you attempt a question you are not sure about, you are not making an educated guess. You are playing a game with stacked odds — three wrong options, one right option, and a negative marking penalty of one-third. For uncertain attempts to make sense, you must get more than three out of four right just to break even. Most aspirants are not close to that threshold on questions they are unsure about.
Inference-Heavy RC: The Real Separator
Recent CAT patterns suggest that inference-based questions now form a significantly higher proportion of RC questions than factual recall questions. These questions are designed to test your ability to tell apart:
- What the passage states vs what it implies
- What the author believes vs what the passage mentions as an external view
- What is logically consistent with the passage vs what seems plausible in the world
This is where strong general readers fall apart. Their reading instinct — which is calibrated for understanding texts in real life — tells them that a plausible, resonant option is likely correct. CAT is calibrated differently. Only what is explicitly supported or directly inferable from the passage is acceptable. Plausibility without textual support is a trap.
Negative Marking Pressure and Decision Fatigue
At the 40+ score level, the numbers are unforgiving. If you attempt 22 questions and get 14 correct, 8 wrong, your raw score is approximately 14×3 – 8×1 = 34. If instead you attempt 16 questions and get 14 correct and 2 wrong, your raw score is 14×3 – 2×1 = 40. Six fewer attempts, six more points.
This arithmetic is not theoretical. Those few marks can lift you from the 80th percentile bracket into the 90th. They can also determine whether a shortlist comes your way.
Add to this the pressure of decision fatigue. By the 25th minute of VARC, many aspirants — especially working professionals who enter the exam after a full workday — begin making subtly worse decisions. Their option evaluation gets less rigorous. Their "this seems right" instinct starts overriding their "is this actually supported?" discipline. And that is precisely when the most avoidable mistakes happen.
The way forward is not sheer willpower, but a disciplined framework.
The VerbalHub 80% Confidence Rule: How It Works

The 80% Confidence Rule is built on one central principle: your decision to attempt or skip a question is itself a skill. It must be practiced deliberately, tracked systematically, and refined over time.
This is what separates high-percentile VARC preparation from generic practice.
The 30-Second Passage Vetting Protocol
Before you attempt a single question from an RC passage, you should spend approximately 30 seconds scanning the passage structure. This is not a reading strategy. It is a selection strategy.
In those 30 seconds, assess:
- Topic familiarity: Can you engage with this material quickly, or will you spend valuable time just decoding the subject?
- Writing style: Is this analytical and argument-driven (easier to track), or dense and abstract (higher cognitive load)?
- Sentence length and structure: Long, convoluted sentences with multiple embedded clauses will slow you down and increase misreading risk.
- Question types visible: If you can see 3–4 inference questions on an abstract humanities passage, that is a warning sign.
Based on this 30-second scan, label the passage:
- A: Engage immediately. High familiarity, clear structure, manageable questions.
- B: Attempt after A passages. Moderate complexity or slightly unfamiliar topic.
- C: Skip entirely or attempt only if time permits. Dense, abstract, or heavily inference-loaded on a topic you find difficult.
This labeling takes practice, but it is learnable. And once learned, it will save you from spending 18 minutes on a C-passage and leaving an A-passage untouched.
A/B/C Confidence Labeling for Individual Questions
Within a passage you are attempting, apply the same logic at the question level:
- A-question: You are confident in your answer after reading the question and evaluating options. Attempt immediately.
- B-question: You have narrowed to two options but cannot eliminate one. Mark and return if time permits. Attempt only if you can eliminate further after a second look.
- C-question: You are genuinely uncertain. Three options still feel possible. Skip without guilt.
The key insight: a C-question is not a bad question. It is a signal from the paper to move on. High-percentile aspirants process this signal faster and more cleanly than lower-percentile aspirants.
Why Skipping 20–25% of Your Section Can Be Intelligent
If you skip 5–6 questions out of 24 in VARC, your effective accuracy on the remaining 18–19 needs to be high. But the math strongly favours this approach:
- 19 attempts, 16 correct, 3 wrong: Score = 48 – 3 = 45
- 24 attempts, 18 correct, 6 wrong: Score = 54 – 6 = 48 (marginally better but at much higher fatigue cost and risk)
- 24 attempts, 15 correct, 9 wrong: Score = 45 – 9 = 36 (this is the likely outcome of undisciplined attempting)
Selective attempting done well is not just risk management. It is performance optimization.
A 40+ VARC score is rarely built on bravery. It is built on disciplined selection.
Inference-Heavy RC: What High Scorers Actually Do Differently
The Author's Opinion vs the Factual Layer
Every RC passage has two layers: the factual layer (what is stated) and the opinion layer (what the author believes, argues, or implies). High scorers are meticulous about keeping these separate.
A common trap: a question asks for the author's view. An option states something factually accurate and consistent with the passage's subject matter — but it represents an external viewpoint the author is analyzing, not endorsing. Students who are reading for understanding often conflate these. Students who are reading for CAT have a trained reflex: who is saying this, and is the author agreeing with it?
Implication vs Exaggeration: The Core Filter
When evaluating inference questions, the decision tree is clean:
- Is this directly stated in the passage? → Likely a strong option.
- Is this implied by what is stated, without requiring additional assumptions? → Could be correct.
- Does this require an assumption beyond what the passage provides? → Almost certainly wrong.
- Is this a generalisation or absolute form of what the passage partially says? → Trap option.
The fourth type is the most dangerous. CAT frequently offers options that take a nuanced, qualified claim from the passage and present it as absolute. The passage might say "in certain industrial contexts, regulation tends to slow innovation." The trap option says "regulation always harms innovation." The difference is obvious in isolation. In a 40-second evaluation window, under exam pressure, it requires genuine discipline to reject the more extreme version.
Practice this explicitly. When reviewing wrong RC answers, always identify: was this an exaggeration trap, an out-of-scope trap, or a true-but-irrelevant trap?
Supported vs Plausible: The Most Important Distinction
If you remember nothing else from this section, remember this: plausible is not the same as supported.
In everyday reading, when an idea feels consistent with what you just read, you tend to accept it. That instinct is appropriate for reading the newspaper. It is catastrophic for CAT RC.
An option is acceptable only if the passage actually supports it — either by stating it directly or by containing evidence from which it follows logically. An option that is plausible, reasonable, or likely-to-be-true in the real world does not qualify unless the passage backs it.
Train this distinction into your review process. Every time you choose a wrong RC answer, ask: was this supported by the passage, or only plausible? More often than not, the latter is the real answer.
The CAT RC Trap Taxonomy
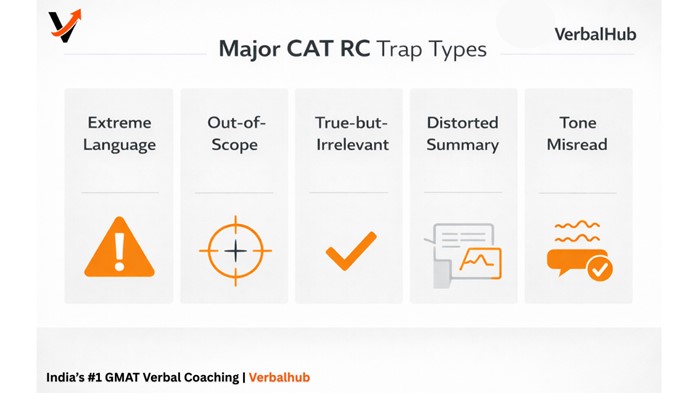
Understanding the categories of wrong options is as important as understanding right answers. Here are the five traps that appear with the highest frequency:
- Extreme Language Traps
Options using absolute words — always, never, every, only, entirely, completely — should trigger immediate caution. CAT passage arguments are almost always nuanced. Absolute options are almost always wrong.
Practice reflex: See an absolute word in an option → slow down and verify whether the passage is equally absolute.
- Out-of-Scope Options
An option that is factually correct, intellectually interesting, and thematically related to the passage — but not actually supported by what is written. This is the trap for well-read aspirants. Your general knowledge creates a false sense of recognition.
Practice reflex: Does the passage say this, or do I know this from elsewhere?
- True-but-Irrelevant Options
The passage contains a relevant fact. An option makes a true statement about that fact. But the question is asking something else entirely. The option is correct — just not as an answer to this question.
Practice reflex: Answer the question that was asked, not the question you wish was asked.
- Distorted Summaries
For inference or main-idea questions, an option may take a real point from the passage and overstate its centrality, or combine two separate points in a way the passage does not.
Practice reflex: Summary options should cover the passage's central thrust — not just one strong point, and not a paraphrase of the last paragraph.
- Emotional Tone Misreads
RC passages on social, political, or ethical topics often have an implied authorial stance. A common trap: an option that assigns the wrong emotional register — "critical" vs "analytical," "concerned" vs "alarmed," "skeptical" vs "dismissive." These distinctions matter.
Practice reflex: Track the author's tone from the beginning. Note shifts. Do not assume the tone based on the topic — derive it from the writing.
Building a Superior Reading Ecosystem for CAT 2026
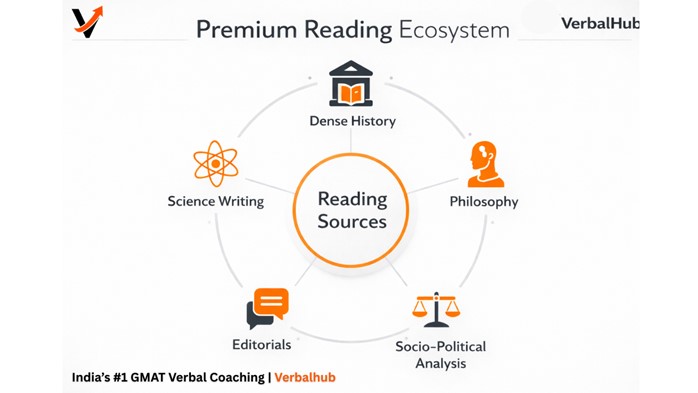
Most VARC advice tells you to "read The Hindu editorial daily." This recommendation still holds value, but on its own it is no longer sufficient. A 40+ VARC score in 2026 requires a more intentional reading diet — one that targets the specific cognitive demands of CAT RC.
CAT passages draw from five broad domains. Your reading practice should reflect this:
- Dense History and Political Philosophy
This trains you to follow multi-layered arguments across time, track causal chains, and distinguish between primary claims and supporting evidence. Sources: Yuval Noah Harari essays, long-form pieces from Aeon, excerpts from works by E.H. Carr or Tony Judt.
- Science and Evidence-Based Writing
CAT science passages require you to understand research logic: hypothesis, evidence, conclusion, limitation. You must distinguish between what a study found and what the author infers from it. Sources: Quanta Magazine, New Scientist long reads, Scientific American essays.
- Philosophy and Abstract Argumentative Writing
The hardest RC passages for most aspirants. Dense, abstract, often about epistemology, ethics, or metaphysics. You need to map the argument’s structure even when the material itself feels hard to process. Sources: Philosophy Now, Stanford Encyclopedia of Philosophy introductory articles, selected essays by Bertrand Russell or Isaiah Berlin.
- Editorials for Tone and Authorial Stance
The real task is to grasp both the content and the delivery — the register, the authorial stance, and the degree of conviction. Sources: Economist leader columns, Mint editorials, Indian Express opinion pieces from senior commentators.
- Socio-Political Analysis for Layered Arguments
Passages where multiple views are presented and the author navigates between them. Your job is to track whose view is whose and where the author stands. Sources: EPW (Economic and Political Weekly), Wire long reads, Foreign Affairs essays.
Daily Reading Checklist
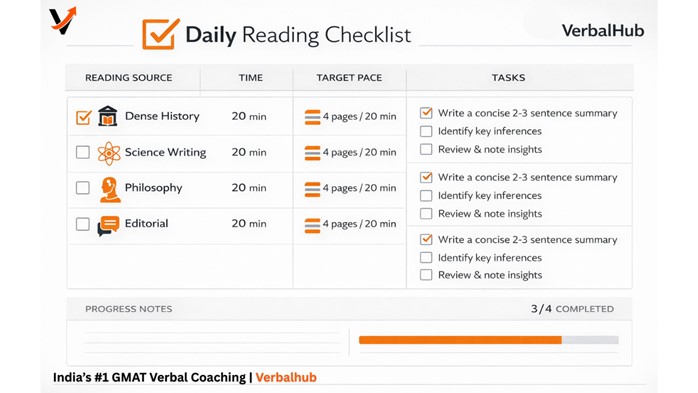
| Reading Source Type | Daily Time | Target WPM | Summary Task | Inference Task | Note-Taking Goal |
|---|---|---|---|---|---|
| Dense history / philosophy | 15 min | 200–220 | Write the central argument in 2 sentences | Identify one implied conclusion | Track authorial stance |
| Science / evidence writing | 10 min | 230–250 | Summarise the evidence chain | Identify what is inferred vs stated | Mark scope boundaries |
| Editorial / opinion | 10 min | 250–280 | Identify the author's position | Spot one assumption the argument relies on | Note the tone and register |
| Socio-political analysis | 10 min | 220–240 | Map the argument's structure | Identify what the author would likely agree or disagree with | Note counterarguments acknowledged |
| RC passage practice (CAT-level) | 20 min | — | — | Practice A/B/C question labeling | Log every wrong answer by trap type |
Total: approximately 65 minutes daily, which is manageable for working professionals who treat this as non-negotiable reading time.
Question Type Analysis: What the Paper Is Actually Testing
Para Jumbles
What it tests: Your ability to identify logical sequence through coherence markers — pronoun reference, cause-and-effect chains, topic introduction logic, and sentence-level signposting.
What high performers do differently: They do not try to read all permutations. They anchor on mandatory first sentences (sentences that introduce a new concept or do not refer back to anything) and mandatory last sentences (sentences that conclude or summarise), then build inward.
Common mistake: Forcing a sequence that sounds fluent without checking logical necessity. A sequence can read smoothly and still be wrong if the reasoning chain is broken.
Attempt logic: Para Jumbles are solvable. Unlike inference RC, they have a definitively correct answer you can verify logically. Do not skip them lightly — they are among the most accuracy-friendly question types if you practice the anchor method.
Skip logic: Skip only if you have worked through the question for more than 2.5 minutes and still cannot eliminate two options. Sunk time is not a reason to commit.
Odd One Out (Para Completion Variant)
What it tests: Your ability to identify the sentence that breaks the coherent set — either thematically, tonally, or logically.
What high performers do differently: They look for the sentence that introduces a new entity, uses a different register, or makes a claim that the other sentences do not support or require.
Common mistake: Choosing the sentence that you find irrelevant to the topic rather than the sentence that breaks the paragraph's internal logic.
Attempt logic: Generally high-yield. Rarely takes more than 90 seconds for a well-prepared aspirant.
Para Summary
What it tests: Your ability to identify the central claim of a paragraph and distinguish it from supporting details, illustrations, or peripheral points.
What high performers do differently: They identify the paragraph's main move — the one claim the rest of the paragraph serves — and look for the option that captures it without over-narrowing (focusing only on one example) or over-broadening (making it too general).
Common mistake: Choosing options that accurately reflect something in the paragraph but focus on a detail rather than the main argument. Also common: choosing options that include information not present in the paragraph.
Attempt logic: Para Summary questions are worth practising in bulk. Accuracy here is buildable quickly. They reward precision reading more than RC inference questions.
The 80% confidence filter here: If two summary options both feel "mostly right," this is a signal to slow down and ask: which one covers the central argument rather than a sub-point?
Para Jumbles with Mandatory Pairs
Some Para Jumble questions come with linked sentences — where one sentence logically must follow another regardless of where they fall in the sequence. Identifying these mandatory pairs first dramatically reduces the solution space.
Practice identifying:
- Pronoun → antecedent pairs (a sentence with "this" or "these" must follow the sentence that introduces the referent)
- Contrast pairs (a sentence beginning with "However" or "But" must follow a sentence it is contrasting with)
- Causal pairs (a sentence explaining a consequence must follow the cause)
CAT VARC Question Type Comparison

| Question Type | Cognitive Load | Avg. Time Required | Accuracy Potential | Skip Threshold |
|---|---|---|---|---|
| RC – Factual / Direct | Low–Medium | 60–90 sec | High (if passage understood) | Low |
| RC – Inference | High | 90–120 sec | Medium | High (if 2+ options equally plausible) |
| RC – Tone / Attitude | Medium–High | 60–90 sec | Medium–High | Medium |
| RC – Main Idea / Title | Medium | 60–75 sec | High (if passage structure clear) | Low |
| Para Jumbles | Medium | 90–150 sec | High (with anchor method) | Medium |
| Odd One Out | Low–Medium | 60–90 sec | High | Low |
| Para Summary | Medium | 75–120 sec | High | Low–Medium |
Why Good Readers Still Underperform in CAT VARC
This is one of the most important sections of this article, and one that is rarely discussed honestly. Many aspirants who read widely, who have strong English instincts, and who score well on verbal ability tests in other formats consistently underperform in CAT VARC. Here is why.
Overconfidence in Reading Instinct
Strong readers trust their comprehension. When they understand a passage well, they feel confident about the questions — and that confidence makes them less rigorous in option evaluation. They go with what "feels right" rather than what is explicitly supported. CAT is designed to punish exactly this.
Poor Option Elimination Process
High scorers do not just identify the right answer. They systematically eliminate wrong answers. The difference is critical: elimination forces you to articulate why an option is wrong, which catches traps that identification-first thinking misses.
Practice a two-pass option evaluation on RC:
- First pass: eliminate obviously wrong options (extreme language, out-of-scope, factually contrary to passage).
- Second pass: among remaining options, apply the "supported vs plausible" test.
No Passage Selection Strategy
Many aspirants read all four RC passages in order, regardless of difficulty. This is the equivalent of playing every hand in poker regardless of the cards dealt. Passage selection is a skill. A C-passage that consumes 18 minutes and yields 2 correct answers has destroyed the time you could have spent getting 4–5 correct on A/B passages.
Reading Without Structure
Reading a passage for general understanding is different from reading a passage for CAT performance. CAT reading requires:
- Active tracking of the argument's structure
- Marking where the author's stance is expressed
- Noting the function of each paragraph (introducing, supporting, conceding, countering, concluding)
- Being alert to scope limitations
Reading without this structure is passive. Passive reading yields lower accuracy on inference questions.
Not Tracking Accuracy by Question Type
Most aspirants review their wrong answers question by question. Few track patterns by question type. If you discover that you are getting 70% accuracy on Para Summary but only 45% on RC inference, your preparation priorities should change immediately. Aggregate tracking creates this visibility. Question-by-question review does not.
Emotional Panic After One Bad RC
CAT VARC is a 40-minute section. A bad start — one difficult RC passage, a Para Jumble that confuses you — can trigger a psychological cascade that affects the next 30 minutes. High-percentile aspirants practice what might be called "passage insulation": the ability to bracket the previous passage completely and begin the next one with a neutral state.
This is a trainable skill. In mock practice, deliberately simulate a bad start — begin with a C-passage, get stuck, then reset mentally before the next passage. Build the recovery reflex.
2-Month VARC Roadmap for Working Professionals
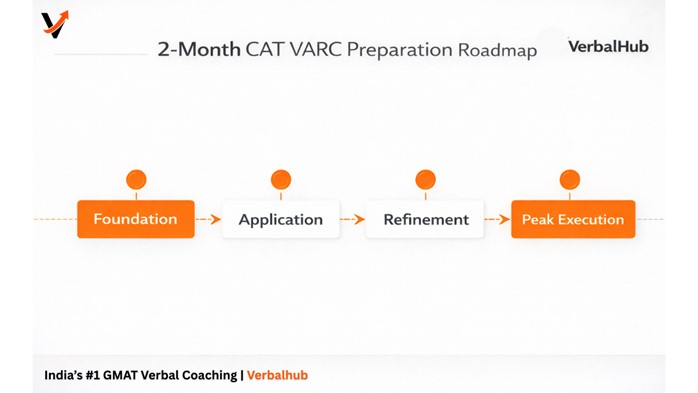
Working professionals face a different preparation challenge than full-time students. Time is compressed. Energy is variable. Consistency beats intensity. The following roadmap is built around these realities.
Phase 1 – Foundation (Weeks 1–2): Build the Baseline
Goal: Establish accurate self-assessment and reading habits.
- Take one diagnostic VARC mock (under timed conditions).
- Identify your current accuracy by question type.
- Begin daily reading from the reading ecosystem described above (50 min/day minimum).
- Practice 3–4 RC passages per day with full error analysis.
- For now, speed is not the priority. Your priority is to understand why every wrong answer is actually wrong.
Key output: A personal accuracy baseline by question type. An error log started.
Phase 2 – Application (Weeks 3–5): Skill Building
Goal: Implement the 80% Confidence Rule in practice and build passage selection instincts.
- Begin applying A/B/C passage labeling on every practice set.
- Begin applying confidence labeling on every question.
- Drill Para Jumbles and Para Summary separately. Track accuracy weekly.
- Incorporate recorded VA drills from VerbalHub to reinforce question-type strategies.
- Begin mock-based practice: one section mock per week under full exam conditions.
Key output: 10–15 percentage point improvement in RC accuracy. Para Summary and Para Jumbles accuracy above 75%.
Phase 3 – Refinement (Weeks 6–7): Pattern Recognition and Mock Analysis
Goal: Move from execution to instinct.
- Two section mocks per week. Full mock analysis after each.
- Use mock heatmaps to identify which question types are accuracy anchors and which are accuracy drains.
- Conduct 1:1 strategy review of your error log. Look for patterns, not individual mistakes.
- Reduce reading time slightly; increase CAT-level RC practice.
- Refine your passage selection instinct based on mock data.
Key output: Consistent VARC score above 35 in mocks. Stable accuracy above 80% on attempted questions.
Phase 4 – Peak Execution (Week 8): Consolidation and Confidence Building
Goal: Stabilize, not expand. Execute what you have built.
- Full mocks only. No new strategies.
- Focus on mental resilience: passage insulation, decision speed, reset drills.
- Review your confidence tracker and error log for one final calibration.
- Ensure sleep, nutrition, and energy management are in order for the real exam.
Key output: Consistent, repeatable performance. Score variance reduced. Exam-day readiness.
2-Month VARC Roadmap Summary Table
| Phase | Weeks | Daily Time | Primary Focus | Key Tools | Target Output |
|---|---|---|---|---|---|
| Foundation | 1–2 | 60–70 min | Baseline + reading habits | Error log, diagnostic mock | Accuracy baseline by type |
| Application | 3–5 | 60–80 min | 80% Rule + question-type drills | Confidence tracker, VA drills | 10–15% accuracy improvement |
| Refinement | 6–7 | 70–90 min | Mock analysis + pattern recognition | Mock heatmaps, 1:1 review | Score above 35, 80%+ attempt accuracy |
| Peak Execution | 8 | 50–60 min | Stabilisation + mental prep | Full mocks only | Consistent, low-variance performance |
Working professionals: the above is designed for 60–80 minutes per day on weekdays and 2–3 hours on weekends. Consistency over 8 weeks outperforms intensive 2-week bursts.
Decision Fatigue and the Low-Energy Workday

This section is specifically for working professionals — and it addresses something most VARC guides completely ignore.
You will not always sit down to prepare at peak energy. There will be evenings after back-to-back meetings where your executive function is genuinely depleted. On those days, your ability to evaluate inference-heavy RC options with precision is measurably worse. What should you do?
Why Accuracy Drops After 25–30 Minutes
The cognitive mechanisms involved in CAT VARC — working memory, inhibitory control (the ability to suppress "almost right" options), and sustained attention — are depleted by extended office work. This is not motivation. It is neuroscience. Aspirants who ignore this and push through anyway often practise with low accuracy, which does two damaging things: it reinforces bad habits, and it creates a misleadingly pessimistic picture of their ability.
Resetting Between Passages
Even on high-energy days, build a 20–30 second reset ritual between RC passages. Close your eyes. Take two deep breaths. Explicitly release the mental residue of the previous passage. This sounds simple — it is underused. The goal is passage insulation: beginning each new passage without cognitive carryover from the previous one.
What to Do on Low-Energy Days
Do not attempt inference-heavy RC on very low-energy evenings. Instead:
- Do Para Jumble drills (lower inference load, more logic-based)
- Do Para Summary practice (shorter passages, bounded task)
- Do reading from your reading ecosystem without any associated practice task
- Review your error log and update your confidence tracker
These tasks keep you consistent without reinforcing bad accuracy patterns. Consistency is the goal — but consistent quality, not consistent volume.
The Minimum Effective Dose
On the most exhausted days, a 20-minute minimum is your commitment: 10 minutes of quality reading (one editorial piece, read actively), and 10 minutes of error log review. This keeps the habit alive without doing damage. Do not skip entirely — The continuity of practice matters more than the result of any one study session.
What Should You Do Starting This Week?
You have the framework. Here is what to do with it immediately.
7-Day Micro-Action Reset Plan
Day 1: Take a diagnostic VARC section (any recent CAT mock paper). Do not target a score — just complete it honestly and log every wrong answer with the error type.
Day 2: Read one long-form article from your reading ecosystem. Time yourself. Identify the central argument and write it in two sentences.
Day 3: Practice 2 RC passages (CAT-level). Apply A/B/C question labeling. Review errors by trap type, not just answer.
Day 4: Do a Para Jumbles-only session — 8–10 questions. Practice the anchor method. Track time per question.
Day 5: Do a Para Summary session — 8–10 questions. After each, articulate in one sentence why each wrong option was wrong.
Day 6: Full VARC section mock (timed). Implement 80% Confidence Rule. Review afterward: what did you skip, and were the skips correct?
Day 7: Update your error log. Identify the one question type with the lowest accuracy. Plan next week's practice to address it specifically.
Your Four Rules Going Forward
One reading rule: Spend a minimum of 30 minutes daily on quality reading from a diverse source. Not news headlines. Not social media. Long-form, argument-driven writing.
One mock rule: Every VARC mock is followed by a full error analysis. Never take a mock without reviewing it.
One review rule: Log every wrong answer by error type (trap type for RC, logic error for VA). Review the log weekly, not daily.
One skip rule: If you cannot reach 80% confidence on a question within your allotted time, skip it. Every time, without negotiation.
FAQ: CAT 2026 VARC
A raw score of 40 in VARC is excellent and typically corresponds to approximately the 88th–92nd percentile, depending on paper difficulty. For calls from IIM A, B, and C, VARC scores of 40+ significantly strengthen your overall profile. It is achievable with a disciplined accuracy-first approach.
Accuracy in CAT RC improves through three practices: first, learning to distinguish between "supported by the passage" and "plausible but unsupported"; second, systematic option elimination (eliminating wrong options rather than identifying right ones); and third, understanding the five RC trap types and training yourself to recognise them quickly. Error log review is the single most effective accuracy-building tool.
Yes, with realistic structuring. Six months is sufficient for a meaningful VARC improvement if you commit to 60–75 minutes daily, practise with an error-tracking system, and follow a phased roadmap. The constraint for working professionals is not time — it is consistency and quality. Twenty disciplined minutes beats ninety distracted minutes every time.
For the CAT VARC reading ecosystem, prioritise: Aeon and Quanta Magazine for abstract and science writing; The Economist and Mint editorials for argument-based editorials; EPW and Foreign Affairs for multi-perspective socio-political analysis; and carefully selected essays from philosophers and historians for abstract argumentation. Rotate across these categories to cover the full spectrum of CAT passage types.
At the 90+ percentile level, high scorers typically attempt 16–20 questions out of 24, with accuracy above 80–85% on attempted questions. For an aspirant targeting 40+, attempting 18–20 questions with 85%+ accuracy is more reliable than attempting 23–24 with 70–75% accuracy. The goal is not maximum attempts — it is maximum accurate attempts.
Yes, if it is genuinely a C-passage — dense, abstract, inference-heavy, and unfamiliar in topic. Skipping a passage you cannot engage with confidently is intelligent strategy, not surrender. Use the saved time to do the remaining passages and VA questions with greater care and precision. The 80% Confidence Rule applies at the passage level too.
Because comprehension alone is necessary, but it is not enough. Most wrong RC answers come from one of three sources: failing to distinguish between what is stated and what is implied; falling into option traps that are plausible but not textually supported; or misreading the authorial tone or stance. Understanding what the passage says is the starting point. Knowing what the passage does not say — and refusing to infer beyond that — is the actual skill.
Prioritise quality over volume. Thirty minutes of active, structured reading practice with an error log is more effective than two hours of passive reading. Build the reading habit into your commute, your lunch break, or a fixed evening slot. Use recorded drills and modular practice rather than only full-length mocks. Track weekly progress by question type, not by raw score alone. And on low-energy days, default to Para Jumbles and Para Summary rather than inference-heavy RC — they keep you consistent without reinforcing bad habits.

Conclusion: The Discipline That Wins VARC
CAT 2026 VARC will not be won by reading speed alone, by vocabulary, or by brute volume of practice. It will be won by aspirants who understand what the section is actually testing — decision quality under uncertainty — and who prepare for it accordingly.
The 80% Confidence Rule is not a trick. It is a discipline. It requires you to be honest about what you know and what you do not, to resist the pull of ego-driven attempting, and to understand that a skipped question costs nothing while a wrong answer costs real marks.
The top 1% of VARC scorers do not read everything better. They reject uncertainty faster.
Your preparation over the next weeks should be built around three pillars: build your reading depth and range systematically; sharpen your inference precision through regular, tracked RC practice; and develop the selection intelligence to know which questions deserve your time and which do not.
A 40+ VARC score is within reach for serious aspirants who treat VARC as a decision-making challenge, not a language test. The framework is here. The roadmap is clear. What remains is consistent, disciplined execution.
Ready to implement this strategy with expert guidance? VerbalHub's CAT VARC programme includes structured RC drills, recorded VA strategy sessions, confidence tracking tools, mock heatmap analysis, and 1:1 strategy reviews — built specifically for aspirants who want 40+ in VARC. Explore our [CAT VARC preparation programme] or take a [free VARC diagnostic] to know exactly where you stand today.
Already working through mocks? Our [CAT mock analysis framework] will show you how to extract maximum learning from every practice test you take.



Our Teachers

Dr. G Ravindra Babu
Quant Faculty
Ph. D in Mathematics Asian International University|| Mathematics Professor at Gitam University || Ex-Mathematics Professor SRM University Amaravathi || MBA in finance Acharya Bangalore B School || GMAT Quant 51, CAT Quant 99.58 %tile, GRE Quant 170 || 21 Different Teaching Certification || Believe in “Education is the mother of leadership”
view details

Dr. Rengarajan Parthasarathy
CAT Faculty
Ph. D in Mathematics from YCM University|| Mathematics Professor at Symbiosis International|| Author of Business Ethics || Ex-CAT Exam Syllabus Advisor in IIM || MBA & MPM from Symbiosis International (Deemed University) || College Topper in Mathematics in Ferguson College || Six Scholarships in Mathematics || 15 Years CAT Coaching, GMAT Coaching and GRE Coaching Experience|| UGC NET Qualified || GMAT Q51, V38 & CAT Q 99.31 & DILR 99.38 %tile, GRE Quant 170 || Believe in “Higher Education Shapes The World.”
view details

Dr. Nisha Tejpal
Verbal & AWA Faculty
Ph. D in English || Published a paper in English in ‘Research Journal of Philosophy and Social Sciences’ || MCA and B.Ed CCS University || A subject expert in Verbal Teaching || 10,000 Plus Essays Analysis || CTET and NET Qualified || More than 15 years of Experience || A writer, Author and Poet || Believe in “Think Beyond the Universe”
view details

Dhrithi Khattar
Verbal Faculty
A subject expert in Verbal Aptitude || More than 15 years of Experience || MBA in HR& Marketing & MA in Economics || Active Member of Hindu Alumni Association || Functional Member of Delhi ||Management Association (DMA) || Operational Member of All India Management Association (AIMA) ||The President of Key Club ||An active member of the French Club ||Gold Seal from California Scholarship Federation.
view details
M. U. Mir
DILR & Quant Faculty
A subject expert in Quantitative Aptitude Training || GMAT Q 51 & CAT DILR 99.75 %tile || GATE 2020 Qualified || M. Tech & B. Tech University Toper (1st Rank) || Awarded by Gov of Odisha, Bihar and J& K for the project Magnetic Floating Model || Ex-Quant Subject Expert in Arihant Publication || An Educationist and Social Worker || Believe in “Education is power”
view details

C. S. Rajawat
CAT Faculty
M. A in Mathematics CCS University|| M. Tech from SRM University || Visiting Mathematics Faculty CCS University ||Experience of 11 Years of CAT Coaching || District Topper in 10th & 12th || Best Teacher Awardee in 2021 & 2022 || CAT Quant 99.43 %tile || Discovered a new Theorem based on HCF in Math || Founder of C. S. Classes ||Believe in “Teaching and Training is an Art.”
view details

Dr. S.K. Singh
PTE/IELTS/CELPIP Expert
Ph. D. English Dr. B. R. Ambedkar University || Delhi & Center Government School Mentor || Founder of Entrepreneur & Learning Startup || IELTS & CELTA Certified from British Council || PTE Certified from Pearson...
view detailsRishabh Arora
PTE/IELTS/CELPIP Expert
MBA in HR International Institute of Management Sciences || PTE Certified from Pearson Test of English|| IELTS & CELTA Certified from British Council || BCA from Integral University || PTE 87 in 2017, IELTS 8.5 in 2018
view details
Jyoti Joshi
IELTS Trainer
Master in English (MA) and Bachelor in Education (B.Ed) || Certified Trainer || IELTS Speaking 9.0 Band holder || Believe in “Great teacher can inspire hope, ignite the imagination, and instill a love of learning”
view details
Surbhi Arora
IELTS / PTE Expert
English Language Expert || More than 3 years of Experience || M.A plus B. Ed Delhi University ||Author, Writer & Classical Singer|| Believe in “Language Language Learning & Teaching is Fun”
view details

Dilip Kumar Rathore
Quant Trainer
A business developer and genius in mathematics || Highly experienced || Master in Maths || well-verse in IT || Believe in “The art of teaching is the art of assisting discover”
view details

Imaam Hasan
Communication Expert
Master in English || Journalist and writer || Certified IELTS & PTE Trainer || A social educater and influencer || Believe in “Education is the movement from darkness to light”
view details
